STAT20029 Module 5 Discrete distributions
Module 5: Discrete distributions
Introduction
Simple probability often explores events that have two outcomes: they either occur or they don’t. We then try to quantify how likely they are to occur by assigning a probability as a number between zero and one. Many real life problems, however, have many possible outcomes. For example, a call centre can receive 0, 1, 2, 3, … complaints in a day or a company may hire a certain number of new employees. These variables are called ‘discrete’ because they only take discrete, non-negative whole number values (hence our topic for the week is discrete distributions). We will be exploring the expected values (or what might occur ‘on average’) for these kinds of variables and determining variance and standard deviations.
Sometimes we are interested in an event which might be repeated many times. For example, on an assembly line in a factory a product might be measured as either acceptable (often referred to as ‘good’) or defective. This outcome will be measured for each of the hundreds of items that are produced each day. We might then be interested in the probability that a certain shipment containing many pieces of items contains less than a certain percentage of defective items. The binomial distribution is useful in helping us describe this kind of situation.
We refer to probability distribution as the complete list of all possible outcomes along with the probability for each. The exhaustive list can take on a tabular form, a graphical form or an equation form.
When the probability of success or failure is very small, another probability distribution known as the Poisson distribution is commonly used. As an example, if we know that, on average, complaints come in to a consumer helpline at three per hour, what is the probability that we might receive more than four complaints in an hour? More than six complaints in an hour? The Poisson distribution (pronounced ‘poy sohn’) can be helpful in answering these sorts of questions.
Before we proceed further with probability distribution, it is important to note that probability is a branch of statistics that comprises of theoretical tools. We will come across many types of theoretical probability distributions and learn about their properties. For a statistician, the challenge is often to find for the real-world data a matching theoretical probability distribution – matching here refers to similarity in the uncertainty of the two.. Once this can be accomplished, we get an in-depth understanding of the real-world process since theoretical probability distributions have been extensively studied.
Objectives
On completion of this module you should be able to:
- find expected value, variance and standard deviation for a discrete random variable
- calculate and interpret covariance
- determine the appropriateness of the binomial distribution for certain situations
- calculate probabilities of events for the binomial distribution
- determine the appropriateness of the Poisson distribution for certain situations and
- calculate probabilities of events for the Poisson distribution.
Probability distributions for a discrete random variable
A random variable is a variable that can take on different values according to the outcome of a chance experiment. Random variables are either described as discrete or continuous.
Discrete random variables can take on non-negative whole numbers and are the result of a counting process. They are used in situations where fractional numbers don’t make sense, generally. Strictly speaking, fractional numbers can sometimes be discrete, for example, money, such as $3.01 since we do not have a denomination smaller than one cent, although some consider money to be a continuous variable.
An upper case letter such as X is used to denote the random variable and the corresponding lower case letter, x, to denote the particular value assumed by the random variable. For example, if the random variable is the number of people who arrive at an ATM per minute, we obviously could not have 3.15 people arrive in a given minute. The number of people arriving could be 0, 1, 2, 3, 4, 5, etc. So if X denotes the number of people who arrive at an ATM per minute, then x is the value 0 or 1 or 2 or 3… etc.
Continuous random variables can take on fractional numbers and are the result of measurement rather than counting. For example, a continuous random variable might involve measuring the amount of petrol (in litres) in a storage container. We will explore continuous random variables in more detail next week.
A probability distribution describes a random variable. It is the relative frequency distribution that should theoretically occur for observations from a population. A discrete probability distribution is a list of all possible outcomes of an experiment with their probability of occurrence.
Given the random variable, X, let xi, where i=1,2,…,k denote the k distinct values that X may assume. Then, the probability that the random variable X will assume value is denoted by P(X=xi ). For example, in the ATM example, the xi values would be , x2=1, x3=2, etc. and then the probability of two people arriving in a given minute would be denoted P(X=2). The probability distribution for the random variable X, associates a probability P(X=xi ) for each of the distinct outcomes xi.
Example 5–1
A quality assurance check is carried out by a manufacturer prior to shipping a particular model of calculator to the retailers. Each calculator is checked for four key problems. If X is the number of problems identified on each calculator, then it can take on the values . The probability distribution then associates a probability with each of these outcome values as follows:
|
x |
0 |
1 |
2 |
3 |
4 |
| P(X=x) |
0.8 |
0.1 |
0.05 |
0.03 |
0.02 |
We know, therefore, that the probability that a calculator has no problems is 0.8, has one problem is 0.1, has two problems is 0.05, etc.
Important notes:
- The probabilities add to 1 (0.8+0.1+0.05+0.03+0.02=1) since one of the possible x value outcomes must occur (there must be either 0, 1, 2, 3 or 4 problems with each calculator).
- All the probabilities associated with each possible outcome are values between 0 and 1 (inclusive).
- Often P(X=xi ) is abbreviated to P(xi ). For example denotes P(X=0), P(1) denotes P(X=1), etc.
We can illustrate the probability distribution graphically as follows:
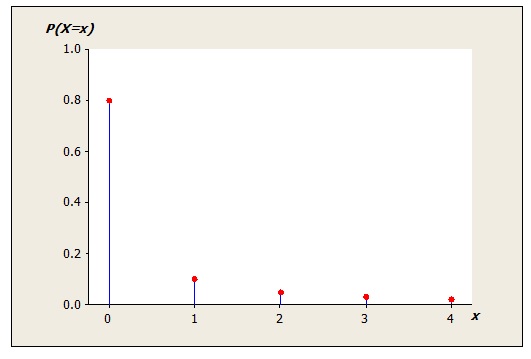
Describing a discrete distribution
Often we would like to know the mean value of a random variable. Since this is a measure of what is expected in the long run it is known as the expected value of a discrete random variable and is defined as:
μ=E(X)=∑(i=1)k〖xi P(X=xi ) 〗
The term E(X) is read as ‘the expected value of X’.
The variance of a discrete random variable is defined as:
σ2=∑(i=1)k〖[xi-E(X)]2 P(X=xi ) 〗
and the standard deviation of a discrete random variable is defined as:
σ=√(σ2 )=√(∑(i=1)k〖[xi-E(X)]2 P(X=xi ) 〗)
Example 5–2
The CEO of a large corporation is concerned that the corporation’s intranet has been suffering with a number of faults and is unavailable much of the time. He arranges for the collection of data which details the number of times where the intranet has been down and for how long for a random sample of three hundred business days. The results are given in the following table:
|
Hours unavailable (per day) |
Frequency |
|
0 |
210 |
|
1 |
24 |
|
2 |
30 |
|
3 |
24 |
|
4 |
6 |
|
5 |
0 |
|
6 |
6 |
- Form the probability distribution for the number of hours per day the intranet was down.
- Compute the mean or expected number of hours that the intranet will be down per day.
- Compute the standard deviation.
What is the probability that on any given day:
- the intranet will be down for fewer than two hours?
- the intranet will not be down at all?
- The intranet will be down for at least three hours?
Covariance and probability in finance
Covariance is a measure of the strength of the relationship between variables. The covariance of two discrete random variables, X and Y, is defined:
σXY=∑(i=1)k[xi-E(X)][yi-E(Y)]P(xi yi )
A positive value indicates a positive relationship between the two variables (as one variable increases, so does the other), a value of zero indicates no relationship, and a negative value indicates a negative relationship (as one variable increases, the other decreases). The relationship between covariance and correlation (ρ) is, ρ=σxy/(σx σy ), where σx and σy are standard deviations of X and Y.
The expected value of the sum of two random variables, X and Y, is equal to the sum of the expected values: E(X+Y)=E(X)+E(Y)
The variance of the sum of two random variables, X and Y, is equal to the sum of the variances plus twice the covariance: var(X+Y)=σ(X+Y)2=σX2+σY2+2σXY
The standard deviation of the sum of two variables is σ_(X+Y)=√(σ(X+Y)2 ). Expectation is a linear operator, where adding (or subtracting) before or after the operation makes no difference. But Variance is a non-linear operator where adding (or subtracting) before or after makes a difference. It is similar to the fact that 〖(a+b)〗2≠a2+b2, rather 〖(a+b)〗2=a2+b2+2ab.
In finance, we might be interested in the expected value and standard deviation of a sum of two investments (indeed more, but we present here the case of only two, however, the principle is the same for more than two). Because we may want to divide an investment into two unequal portions, we will use w to represent the portion assigned to one asset and (1-w) the portion assigned to the other. Using the expected value and standard deviation formulae above, we can derive the following.
The portfolio expected return for a two asset investment is defined:
E(P)=wE(X)+(1-w)E(Y)
where E(P) is the expected portfolio return, E(X) is the expected return of asset X, E(Y) is the expected return of asset Y, is the portion of the portfolio value assigned to asset X and (1-w) is the portion of the portfolio value assigned to asset Y.
The portfolio risk is defined:
σp=√(w2 σX2+(1-w)2 σY2+2w(1-w) σXY )
Example 5–3
One of your clients is deciding how they should invest a sum of money. They have obtained a report giving the predicted annual return for a $1000 investment in two different stocks. The following probability distribution was included in the report.
|
Probability |
Stock J |
Stock K |
|
0.2 |
–$50 |
–$105 |
|
0.2 |
$10 |
$2 |
|
0.4 |
$30 |
$25 |
|
0.2 |
$100 |
$200 |
Determine the following values:
- The expected return of stock J
- The expected return for stock K
- The standard deviation for stock J
- The standard deviation for stock K
- The covariance of stock J and stock K
- Based on your answers above, what recommendations might you make to the client. Explain.
Example 5–4
Returning to the scenario in Example 5–3, compute the portfolio expected return and the portfolio risk if 90% of the stock is invested in stock J. Repeat when 50% of the stock is invested in stock J.
Notes on rounding
All final answers that are money amounts must be rounded to exactly 2 decimal places (for dollars and cents) and must include the dollar sign. The only exception is if the value is whole dollars, when 0 decimal places are acceptable (but clearly a dollar sign is still required). But, don’t round intermediate steps of working or you will introduce a rounding error (and be marked wrong in assessment items). Some examples:
|
Correct: |
$4.57 |
$100.95 |
$5,984.56 |
$495 |
ü |
|
Incorrect: |
$4.6 |
$100.9543 |
û |
When rounding other numbers, use your common sense. In general, larger numbers need fewer decimal places and smaller number needs more. A good rule of thumb (and it is a requirement in the exam) is to keep four significant digits in your final answers. But always keep all the decimal places in intermediate steps of working—using the memory on your calculator will help you do this.
Please learn about what is meant by significant number of digits if you already don’t know it. The numbers 1234000.00, 23.74, 0.00001234, 0.00001001, 1.002, 5091000000 have each four significant digits.
The binomial distribution
A Bernoulli random trial is a trial that has two possible outcomes. These are assigned either the value 0 or 1. A random variable, X, that is associated with a Bernoulli random trial is called a Bernoulli random variable. Some examples are:
- Students sitting a particular exam either receive a pass grade (assigned the value X=1) or a fail grade (assigned the value X=0). Here X is a Bernoulli random variable.
- Last year, a company forecast expected profit for the financial year. At the end of that year they will have either met the forecasted profit (X=1) or failed to meet it (X=0). Again, X is a Bernoulli random variable.
- The throw of coin results in either a Head or a Tail (provided the coin does not stand on the edge).
In many situations, we are more interested in the outcome of a sequence of Bernoulli trials, rather than a single trial. For example, we might be interested in the number of students in the class who received pass grades in the exam or the number of years where the company met their forecast profits.
We denote the series of n Bernoulli trials as X1,X2,…,Xn. The sum of n independent and identically distributed Bernoulli random variables is denoted by X:
X=X1+X2+⋯+Xn.
Then X is called a binomial random variable.
Notice that we have assumed the n trials are independent and identically distributed. Independent means that the two events (or trials) are statistically independent. In other words, the outcome of one trial does not affect the outcome of any other trial. Identically distributed means that the probability of X_i=1 and X_i=0are the same for all Bernoulli trials in the sequence. Usually we denote this as P(X_i=1)=p and P(X_i=0)=1-p for . So in the exam example above, p is the probability that a particular student receives a passing grade in the exam. Therefore, the probability that they don’t receive a passing grade (i.e., they receive a failing grade) is 1-p.
The probability of a particular outcome of a discrete random variable, X, is expressed as P(X=x) or just P(x). For a binomial random variable, this can be expressed using the following mathematical formula:
P(X=x)=((n@x)) px (1-p)(n-x)
Notice that this includes the binomial coefficient (■(n@x)) which is the combinations formula we first encountered in Week 4.
For the binomial distribution to be appropriate, the random variable must have the following characteristics:
- there are a fixed number of trials (called n),
- each trial has two mutually exclusive and collectively exhaustive outcomes (called ‘success’ and ‘failure’),
- the probability of success, p, is constant across all trials and the probability of failure , 1-p , is also constant across all trials and
- the outcome of any trial is independent of the outcome of any other trial. If sampling is done without replacement from an infinite population or if sampling is with replacement from a finite population this helps to ensure independence.
{`The value of p determines the skewness of the binomial distribution. For p=0.5, the binomial distribution will be symmetrical, for p<0.5 the distribution will be skewed to the right and for p>0.5 the distribution will be skewed to the left.`}
The mean, or expected value, of the binomial distribution is given by:
μ=E(X)=np
where n is the number of trials and p is the probability of success. The standard deviation of the binomial distribution is given by:
σ=√(σ2 )=√(var(X) )=√(np(1-p) )
Example 5–5
An accountant works mainly with personal income tax cases. He knows from past experience that the probability of a customer being satisfied with the service he offers is 0.8. Given that he sees 8 clients today, determine the probability that:
- all 8 customers are satisfied
- at least 6 customers are satisfied
- fewer than 5 customers are satisfied
- What assumptions are necessary in (a) to (c)?
What are the mean and standard deviation of the probability distribution?
The Poisson distribution
The Poisson distribution describes situations where we are interested in the number of occurrences of a particular event in a certain period, for example, the number of mobile phones sold per week or the number of people calling a helpline per day. It is also used for rare events such as the number of accidents at a street intersection.
The probability of a particular event for a Poisson random variable can be expressed using the following mathematical formula:
P(X=x)=(e(-λ) λx)/x!
where λ (Greek letter ‘lambda’) is the expected number occurrences of the event per time period.
The Poisson distribution is always skewed to the right, however, the larger the value of λ, the more symmetrical it becomes.
The mean and variance of the Poisson distribution are:
μ=E(X)=λ
σ2=var(X)=λ
For the Poisson distribution to be appropriate, the random variable must have the following characteristics:
- interest is in counting the number of occurrences of an event within an interval (which could be time, distance, area, etc.)
- the probability of an event in a given interval is the same for all intervals
- the number of occurrences of an event in an interval is independent of the number of occurrences in any other interval and
- the probability of two or more occurrences of an event in an interval approaches zero as the size of the interval approaches zero.
Example 5–6
A new call centre is being set up for a large telephone company. Based on experience at their other similar centres, they expect that calls will come in at an average of 10 per minute. In order to plan their staffing requirements, the company would like to answer the following questions:
(a) What is the probability that less than five calls will be received in any given minute?
(b) What is the probability that at least twenty calls will be received in any given minute?
(c) What is the probability that between seven and thirteen calls will be received in any given minute?
Discussion points
Discussion point 5–1
{`Look at the Practical Example below and its solution. From the example, discuss how the formula for the binomial distribution was derived, what is meant by probability distribution, and the convention that a set is defined within braces {…} and “” represents union and “” represents intersection of sets.`}
Discussion point 5–2
Discuss the difference between binomial and Poisson distributions.
Summary
Now that you have completed this module, turn back to the objectives at the beginning of the module. Have you achieved these objectives?
Ensure that you attempt the recommended problems in the list of review questions below and at least a sample of problems from the optional list. This will help you to identify any areas of difficulty you have in achieving the module’s objectives.
Tutorial and Workshop
|
A Practical Example Problem demonstrating the development of binomial distribution: The manager of the Tammi Shoe store has observed over the years that one out of five customers who enter the store buy something. What is the probability that from the next three customers who walk in (a) no one will buy anything? (b) only one person will buy something? (c) only two persons will buy something? (d) all three persons will buy something? Workshop Practice with the following important Excel Function Keys: 1. If you press F1 , it will display the Help page. 2. If you select a cell and press F2 , it will take the cursor to the end of the content of that cell. 3. SHIFT + F3 displays the Insert Function dialog box. 4. When you are writing a formula that has a cell reference, pressing F4 will fix (or make static) that cell reference. 5. F5 displays the Go To dialog box. 6. F11 forces Excel to draw a graph of data in the current range. 7. F12 displays the Save As dialog box. Watch the following video on how to create a macro in Excel: https://www.youtube.com/watch?v=sc9nkncpcPk Tutorial Solve the recommended problems under Review questions. |
